The machine learning revolution: General principles and impact on SEO
I bring to your attention translation of the article "the machine learning Revolution," authored by Eric Ania (Eric Enge).
Machine learning is itself a serious discipline. It is actively used all around us, and in a much more serious scale than you can imagine. A few months ago I decided to delve into this topic to find out more about her. In this article I will talk about some basic principles of machine learning, as well as share your thoughts about its impact on SEO and digital marketing.
For reference, I recommend to watch the presentation Rand Fishkin "SEO in a Two Algorithm World", where Rand examines the impact of machine learning on search and SEO. To this subject I shall return.
I'll also mention a service that allows you to predict the chances of retweet of your post on the basis of the following parameters: figure Followerwonk Social Authority, having images, hashtags and other factors. I called this service Twitter Engagement Predictor (TEP). To develop such a system I had to create and train the neural network. You specify the initial parameters of the tweet, the service processes them and predicts the chances of retweet.
TEP uses the findings of a study published in December 2014 "Twitter engagement" (involvement in Twitter), where we analyzed 1.9 million original tweets (excluding retweets and favorites) to determine the main factors that affect getting retweets.
the
My first idea about machine learning I received in 2011, when interviewed googler Peter Norvega who told me how to use this technology Google teaches Google Translate.
In short, they collect information on all translations of a word in the network and based on these data, provide the training. This is a very serious and complex example machine learning, Google used it in 2011. It is worth saying that today all leaders of the market — for example, Google, Microsoft, Apple, and Facebook use machine learning to many interesting directions.
Back in November when I wanted to seriously understand this topic, I started searching for articles online. I soon found a great course machine learning on Coursera. It teaches Andrew Ng (Andrew ng) from Stanford University, the course gives you a good idea about the basics of machine learning.
Note: the Course is quite extensive (19 lessons, each takes about an hour or more). It also requires a certain level of preparation in mathematics to understand computations. During the course you will be immersed in math with the head. But here's the thing: if you have the necessary background in mathematics and are determined, it is a good opportunity to get a free course to learn the canons of machine learning.
In addition, Eun will show you many examples in the language Octave. On the basis of the material studied you will be able to develop your own machine learning systems. That's what I did in the example program from the article.
the
First of all, let me make one thing clear: I am not a leading expert in the field of machine learning. However, I learned enough to tell you about some basic provisions. In machine learning it is possible to allocate two main ways: supervised training and unsupervised learning. To begin, I will consider learning with a teacher.
the
At a basic level, you can imagine the learning with the teacher as the creation of a series of equations to match known data set. Let's say you need an algorithm to assess the value of the property (this example uses Eun often in the Coursera course). Let's take some data that will look like the following:
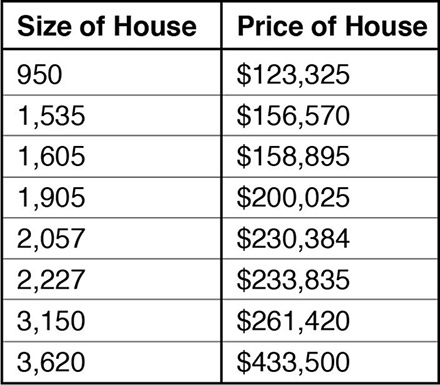
In this example, we have a (fictional) historical data that demonstrates the value of the home depending on its size. As you can see, the larger the house, the more expensive it is, but this dependence does not lie on a straight line. However, we can calculate such a line that pretty well matches the original values, it will look like this:
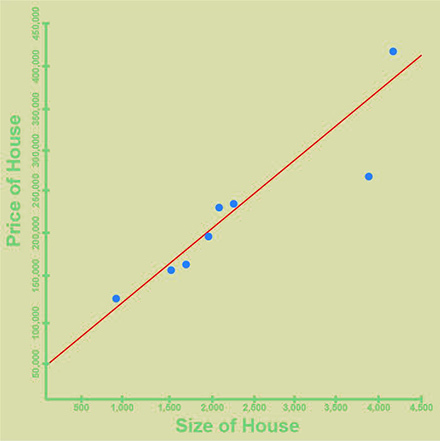
This line can be used to predict the prices of new homes. We consider the size of the house as the "input" parameter and the predicted algorithm as an "out" parameter.
Overall, this model is quite simplified. After all, there are other significant factors that affect the price of real estate is the number of bedrooms, number of bedrooms, number of bathrooms, total square. On this basis, we can build a more complex model, with a data table like this:
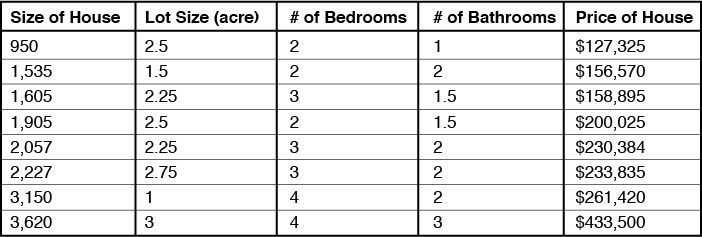
Note that for this version of the video will not work, we need to assign to each factor its weight in forecasting prices. Perhaps, the main factors are the size and area of the house, but the rooms, bedrooms and bathrooms also require weight. All of these factors will be used as input parameters.
Even now, our model is rather simplified. Another significant factor in real estate prices is location. Prices in Seattle (Washington state) differ from the prices in Galveston (Texas). If you try to build such an algorithm on a national scale, using location as an additional input parameter, you will face serious problem.
Machine learning can be used to solve all the above problems. In each example we used sets of data (often called "training sample") to run programs, the algorithm of which is based on compliance data. This method allows you to use the new input parameters for predicting the outcome (in our case, prices). Thus, the method of machine learning where the system is trained based on the training samples is called "supervised learning".
the
There is a special type of task in which the main purpose is to predict specific results. Imagine for example that we want to determine the probability that a newborn will eventually grow at least to 6 feet (~183 cm). The input data set will look like this:

The output of this algorithm we will get the value 0 if the person is likely to be lower than 183 cm and a value of 1 if growth is projected above the set. To solve this classification problem, we specify the input parameters for a specific class. In this case, we are not trying to determine the exact height, but simply the predicted probability that it will be above or below the setpoint.
Examples of the more complex issues of the classification is the recognition of handwritten text or spam emails.
the
This method of machine learning used in the absence of training samples. The idea is to teach the system to distinguish groups of objects with common properties. For example, we can have the following dataset:
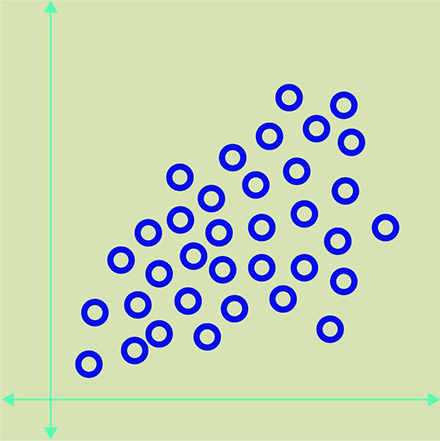
The algorithm analyzes the data and groups them based on common properties. The example below shows the object "x" have the common properties:
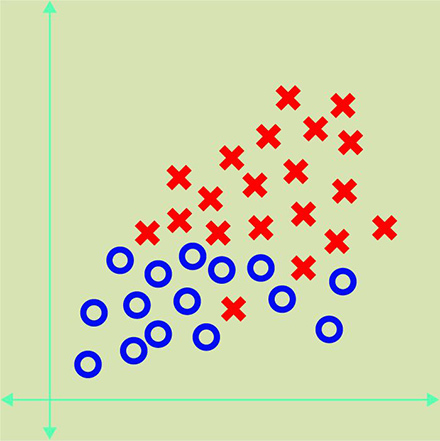
However, the algorithm can make mistakes in the recognition of objects and group them like this:
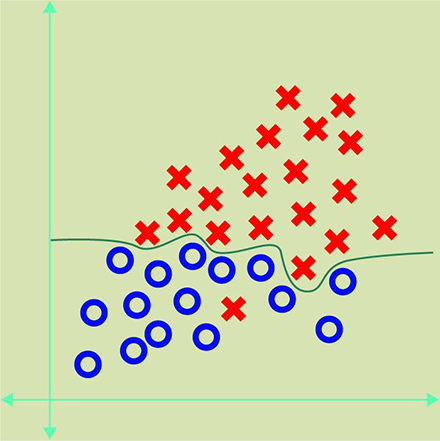
Unlike supervised learning, the algorithm identified the parameters peculiar to each group, and grouped them. One example implementation of the system of learning without a teacher is Google News. Look at the following example:
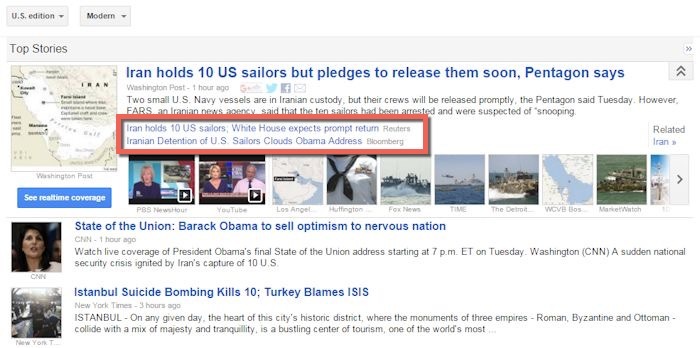
We see the news about the arrest by Iran of 10 American sailors, as well as links to related news agencies Reuters and Bloomberg (circled in red). Group the news is a good example of machine learning where the algorithm learns to find the relationship between objects and combine them.
the
A wonderful example of the use of machine learning is the algorithm for determining the author of that Moz is implemented in your service content. Learn about this algorithm more here. The article at the link details the problems that professionals from Moz had to face and how they solved the task.
Now let's talk a little bit about is mentioned in the beginning of the article service Twitter Engagement Predictor, whose system is built on the basis of a neural network. An example of his work can be seen on the screenshot:
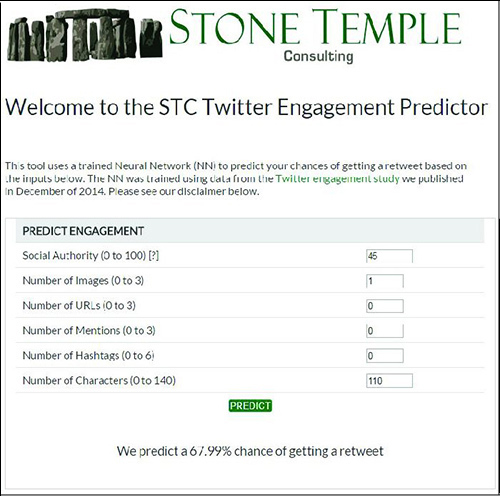
The program makes binary forecast retinal your post or not, in the case of a positive answer calculate the probability of a retweet.
In the analysis of source data used for training the network can detect a lot of interesting nuances, for example:

The table shows the statistics for tweets users by Social Authority level from 0 to 9, without images, without links and mentions containing 2 hastega and 0 to 40 characters of text. 1156 we can see such tweets without retweets and only 17 tweets retweeted from.
Our algorithm shows that with high probability a tweet with such parameters will not get retweeted, but this prediction is incorrect for 1.4% of cases (17 out of 1173). The neural network predicts the probability of receiving a retweet 2.1%.
I calculated table of possible cases and found that we had 102045 examples, the possibility of error, or approximately 10% of the whole training sample. This means that the neural network will make accurate predictions at best for 90% of situations.
In addition, I ran two additional sets of data (containing 470к and 473к examples) using a neural network to evaluate the accuracy of TEP. In absolute prognosis (Yes/no), the system was right in 81% of cases. Given that there is also present about 10% of the examples with a possible error, we can say that the result is pretty good! For this reason, the TEP service additionally shows the retweet probability in percent, instead of the usual forecast (Yes/no).
the
Now that we understand the basic methods of machine learning, let's move on to the second part of the article and see what Google can use these methods:
the
One approach to the implementation of the algorithm Google Penguin can be build a relationship between the reference characteristics, which may be potential indicators of link spam:
Of course, the line links to only one of these factors doesn't necessarily make it "bad", but the algorithm can identify sites where a significant part of the external links has the specified properties.
Me forth example demonstrates a system of supervised learning, where you train the algorithm on the basis of existing data on the good and bad links (sites), discovered in recent years. After training of the algorithm it can be used to verify links to determine their "quality". Based on the percentage of "bad" links (and/or PageRank) can make the decision to lower the rating of the website in the search or not.
Another approach to solving this problem involves the use of a database of good and bad references where the algorithm itself determines their characteristics. With this approach, the algorithm will find additional factors that people do not notice.
the
After we examined the potential of the algorithm Penguin, the situation seems clearer. Now suppose the algorithm estimates the quality of the content.
For this task, you can train the algorithm on the basis of examples of good websites to highlight their qualitative characteristics.
As in the case of the Penguin above, I in no case do not claim that exactly these items are used in the algorithm Panda – they only illustrate the General concept of how this can work.
the
The key to understanding the degree of impact of machine learning on SEO lies in the question of why Google (and other search engines) uses these methods. It is important that there is a strong correlation between the quality of organic results of issuance and revenue from Google contextual advertising.
Back in 2009, Bing and Google conducted a number of experiments which showed that the emergence of even small delays in the search results, greatly affect the user experience. In turn, less satisfied users clicked on fewer ads, and search engines receive less income:
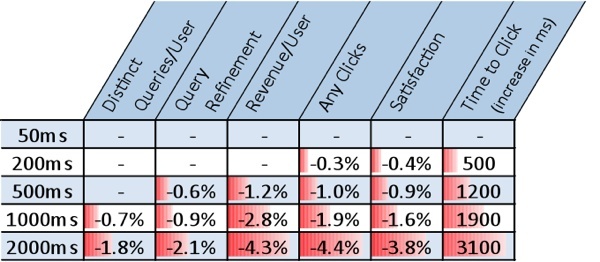
All this is explained very simply. Google has plenty of competitors, and it's not just Bing search. Fight for audience in other (non-search) services is a form of competition. There is already Facebook connect, Apple/Siri and Amazon. There are many alternative sources for obtaining and sharing information, and every day they are working to become better. Therefore, Google needs.
I have already suggested that machine learning can be used in the algorithms Penguin and Panda, and it may be part of a global estimation algorithm of "search quality". Most likely, you will see many more examples of the use of such algorithms in the future.
the
Given that improving user satisfaction is crucial to Google, we should consider this figure as the main ranking factor for SEO. You need to learn how to measure it and increase your score with time. I recommend to ask yourself the following questions:
Article based on information from habrahabr.ru
Machine learning is itself a serious discipline. It is actively used all around us, and in a much more serious scale than you can imagine. A few months ago I decided to delve into this topic to find out more about her. In this article I will talk about some basic principles of machine learning, as well as share your thoughts about its impact on SEO and digital marketing.
For reference, I recommend to watch the presentation Rand Fishkin "SEO in a Two Algorithm World", where Rand examines the impact of machine learning on search and SEO. To this subject I shall return.
I'll also mention a service that allows you to predict the chances of retweet of your post on the basis of the following parameters: figure Followerwonk Social Authority, having images, hashtags and other factors. I called this service Twitter Engagement Predictor (TEP). To develop such a system I had to create and train the neural network. You specify the initial parameters of the tweet, the service processes them and predicts the chances of retweet.
TEP uses the findings of a study published in December 2014 "Twitter engagement" (involvement in Twitter), where we analyzed 1.9 million original tweets (excluding retweets and favorites) to determine the main factors that affect getting retweets.
the
My journey in machine learning
My first idea about machine learning I received in 2011, when interviewed googler Peter Norvega who told me how to use this technology Google teaches Google Translate.
In short, they collect information on all translations of a word in the network and based on these data, provide the training. This is a very serious and complex example machine learning, Google used it in 2011. It is worth saying that today all leaders of the market — for example, Google, Microsoft, Apple, and Facebook use machine learning to many interesting directions.
Back in November when I wanted to seriously understand this topic, I started searching for articles online. I soon found a great course machine learning on Coursera. It teaches Andrew Ng (Andrew ng) from Stanford University, the course gives you a good idea about the basics of machine learning.
Note: the Course is quite extensive (19 lessons, each takes about an hour or more). It also requires a certain level of preparation in mathematics to understand computations. During the course you will be immersed in math with the head. But here's the thing: if you have the necessary background in mathematics and are determined, it is a good opportunity to get a free course to learn the canons of machine learning.
In addition, Eun will show you many examples in the language Octave. On the basis of the material studied you will be able to develop your own machine learning systems. That's what I did in the example program from the article.
the
the Main provisions of the machine learning
First of all, let me make one thing clear: I am not a leading expert in the field of machine learning. However, I learned enough to tell you about some basic provisions. In machine learning it is possible to allocate two main ways: supervised training and unsupervised learning. To begin, I will consider learning with a teacher.
the
Machine learning with the teacher
At a basic level, you can imagine the learning with the teacher as the creation of a series of equations to match known data set. Let's say you need an algorithm to assess the value of the property (this example uses Eun often in the Coursera course). Let's take some data that will look like the following:
In this example, we have a (fictional) historical data that demonstrates the value of the home depending on its size. As you can see, the larger the house, the more expensive it is, but this dependence does not lie on a straight line. However, we can calculate such a line that pretty well matches the original values, it will look like this:
This line can be used to predict the prices of new homes. We consider the size of the house as the "input" parameter and the predicted algorithm as an "out" parameter.
Overall, this model is quite simplified. After all, there are other significant factors that affect the price of real estate is the number of bedrooms, number of bedrooms, number of bathrooms, total square. On this basis, we can build a more complex model, with a data table like this:
Note that for this version of the video will not work, we need to assign to each factor its weight in forecasting prices. Perhaps, the main factors are the size and area of the house, but the rooms, bedrooms and bathrooms also require weight. All of these factors will be used as input parameters.
Even now, our model is rather simplified. Another significant factor in real estate prices is location. Prices in Seattle (Washington state) differ from the prices in Galveston (Texas). If you try to build such an algorithm on a national scale, using location as an additional input parameter, you will face serious problem.
Machine learning can be used to solve all the above problems. In each example we used sets of data (often called "training sample") to run programs, the algorithm of which is based on compliance data. This method allows you to use the new input parameters for predicting the outcome (in our case, prices). Thus, the method of machine learning where the system is trained based on the training samples is called "supervised learning".
the
classification
There is a special type of task in which the main purpose is to predict specific results. Imagine for example that we want to determine the probability that a newborn will eventually grow at least to 6 feet (~183 cm). The input data set will look like this:
The output of this algorithm we will get the value 0 if the person is likely to be lower than 183 cm and a value of 1 if growth is projected above the set. To solve this classification problem, we specify the input parameters for a specific class. In this case, we are not trying to determine the exact height, but simply the predicted probability that it will be above or below the setpoint.
Examples of the more complex issues of the classification is the recognition of handwritten text or spam emails.
the
Machine learning without a teacher
This method of machine learning used in the absence of training samples. The idea is to teach the system to distinguish groups of objects with common properties. For example, we can have the following dataset:
The algorithm analyzes the data and groups them based on common properties. The example below shows the object "x" have the common properties:
However, the algorithm can make mistakes in the recognition of objects and group them like this:
Unlike supervised learning, the algorithm identified the parameters peculiar to each group, and grouped them. One example implementation of the system of learning without a teacher is Google News. Look at the following example:
We see the news about the arrest by Iran of 10 American sailors, as well as links to related news agencies Reuters and Bloomberg (circled in red). Group the news is a good example of machine learning where the algorithm learns to find the relationship between objects and combine them.
the
Other examples of using machine learning
A wonderful example of the use of machine learning is the algorithm for determining the author of that Moz is implemented in your service content. Learn about this algorithm more here. The article at the link details the problems that professionals from Moz had to face and how they solved the task.
Now let's talk a little bit about is mentioned in the beginning of the article service Twitter Engagement Predictor, whose system is built on the basis of a neural network. An example of his work can be seen on the screenshot:
The program makes binary forecast retinal your post or not, in the case of a positive answer calculate the probability of a retweet.
In the analysis of source data used for training the network can detect a lot of interesting nuances, for example:
The table shows the statistics for tweets users by Social Authority level from 0 to 9, without images, without links and mentions containing 2 hastega and 0 to 40 characters of text. 1156 we can see such tweets without retweets and only 17 tweets retweeted from.
Our algorithm shows that with high probability a tweet with such parameters will not get retweeted, but this prediction is incorrect for 1.4% of cases (17 out of 1173). The neural network predicts the probability of receiving a retweet 2.1%.
I calculated table of possible cases and found that we had 102045 examples, the possibility of error, or approximately 10% of the whole training sample. This means that the neural network will make accurate predictions at best for 90% of situations.
In addition, I ran two additional sets of data (containing 470к and 473к examples) using a neural network to evaluate the accuracy of TEP. In absolute prognosis (Yes/no), the system was right in 81% of cases. Given that there is also present about 10% of the examples with a possible error, we can say that the result is pretty good! For this reason, the TEP service additionally shows the retweet probability in percent, instead of the usual forecast (Yes/no).
the
Examples of algorithms that can be used by Google
Now that we understand the basic methods of machine learning, let's move on to the second part of the article and see what Google can use these methods:
the
the Penguin Algorithm
One approach to the implementation of the algorithm Google Penguin can be build a relationship between the reference characteristics, which may be potential indicators of link spam:
-
the
- External link posted in the footer; the
- External link posted in the sidebar; the
- the Link is close to the word "Advertising" (and/or similar) the
- Link are placed close to the image on which is written the word "Advertising" (and/or similar) the
- Link located in the block with links that have low relevance to each other; the
- link Anchor text irrelevant to the page content. the
- External link placed in the navigation area; the
- external links is no separate style (highlighting or underlining); the
- Link located on the "bad" type of site (paspaley directory; from a country unrelated to the website); the
- ... Other factors
Of course, the line links to only one of these factors doesn't necessarily make it "bad", but the algorithm can identify sites where a significant part of the external links has the specified properties.
Me forth example demonstrates a system of supervised learning, where you train the algorithm on the basis of existing data on the good and bad links (sites), discovered in recent years. After training of the algorithm it can be used to verify links to determine their "quality". Based on the percentage of "bad" links (and/or PageRank) can make the decision to lower the rating of the website in the search or not.
Another approach to solving this problem involves the use of a database of good and bad references where the algorithm itself determines their characteristics. With this approach, the algorithm will find additional factors that people do not notice.
the
Algorithm Panda
After we examined the potential of the algorithm Penguin, the situation seems clearer. Now suppose the algorithm estimates the quality of the content.
-
the
- Small amount of content compared to the pages of your competitors; the
- is not wide Enough synonyms in the text; the
- Abuse of keywords on the page; the
- Large blocks of text located at the bottom of the page; the
- Many links are not related within the meaning of the page; the
- of Pages copied from the other websites content; the
- ... Other factors
For this task, you can train the algorithm on the basis of examples of good websites to highlight their qualitative characteristics.
As in the case of the Penguin above, I in no case do not claim that exactly these items are used in the algorithm Panda – they only illustrate the General concept of how this can work.
the
How machine learning affects SEO
The key to understanding the degree of impact of machine learning on SEO lies in the question of why Google (and other search engines) uses these methods. It is important that there is a strong correlation between the quality of organic results of issuance and revenue from Google contextual advertising.
Back in 2009, Bing and Google conducted a number of experiments which showed that the emergence of even small delays in the search results, greatly affect the user experience. In turn, less satisfied users clicked on fewer ads, and search engines receive less income:
All this is explained very simply. Google has plenty of competitors, and it's not just Bing search. Fight for audience in other (non-search) services is a form of competition. There is already Facebook connect, Apple/Siri and Amazon. There are many alternative sources for obtaining and sharing information, and every day they are working to become better. Therefore, Google needs.
I have already suggested that machine learning can be used in the algorithms Penguin and Panda, and it may be part of a global estimation algorithm of "search quality". Most likely, you will see many more examples of the use of such algorithms in the future.
the
so what does that mean?
Given that improving user satisfaction is crucial to Google, we should consider this figure as the main ranking factor for SEO. You need to learn how to measure it and increase your score with time. I recommend to ask yourself the following questions:
-
the
- does the content of your page is the expectation of most users? If the user is interested in your product, does he need help choosing? Does he need tips on using the product?
- does your page better than a page of competitors? the
- How do you measure the quality of pages and improve them over time? Google has numerous ways by which you can evaluate the quality of your page and use this data to change its rank in the search results. Here are some of them:
- How long users linger on the page and how this number differs from the competition? the
- What level of CTR have a page on your website compared to competitors? the
- Many users are coming to your site through branded queries? the
- If you have a page of a specific product, you provide more detailed or brief information about it compared to competitors? the
- when the user returns from your website to the search results, does it continue to surf other sites or enter another request?
How about related intentions? If a user came to you for a particular product, what related products might find interesting?
What is missing in the content of your page? the
-
the
the
Conclusion
Machine learning is rapidly spreading. Obstacles to learning the underlying algorithms disappear. All of the major companies on the market in one way or another used machine learning methods. Here is a little what machine learning uses Facebook, but actively recruits professionals machine learning Apple. Other companies provide a platform to facilitate the introduction of machine learning, for example, Microsoft and Amazon.
People engaged in the field of SEO and digital marketing, we can expect that the top companies will actively develop algorithms to solve their problems. Therefore it is better to focus on the work in accordance with the main objectives of the market leaders.
In the case of SEO, machine learning will raise the bar for quality content and experiences for users to interact. It's time to consider all of these factors in their marketing strategies to get on Board a rapidly moving liner technology.


Комментарии
Отправить комментарий