PostgreSQL load testing using JMeter, Yandex.Tank and Overload
a Few words to start
so, this manual is suitable for those looking for a versatile Toolkit for testing large pool of systems and solving most problems on stress testing. This article is intended for beginners in this business, so I will try to Refine and simplify the process. Discuss briefly each of the elements in our bunch and move on to their primary installation and configuration:
-
the
- Apache JMeter – load testing tool, which is able to carry out tests for JDBC connections, FTP, LDAP, SOAP, JMS, POP3, IMAP, HTTP and TCP out of the box and many other protocols and solutions using various plugins. the
- Yandex.Tank is a cloud – based tool for load testing uses different load generators, including and JMeter. the
- Yandex.OverLoad – the service for easy monitoring and analysis of servers under load.
the
Installation and configuration
the key to success for proper installation of JMeter is the correct java installation. At this stage it is worth saying that all the manipulation will continue to occur under Linux. The official website is a good manual with all details:
-
the
- Installation the 32-bit version of Java. the
- Installation the 64-bit version of Java.
With Java understood for a reference check do java-version in console, the answer should be something like this:

Now go to Apache JMeter. You can put any version of JMeter, but if there are problems such as “Error in NonGUIDriver” then most likely the tank needs a new version or you can easily go to exactly working 2.13. Go back to the installation — it is the same for all versions:
Download client:
wget https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-2.13.tgzExtract:
tar-zxvf apache-jmeter-2.13.tgzJMeter already installed and will work. For initial setup will be sufficient to make only one change. Go down the path of apache-jmeter-2.13/bin open for editing the file jmeter without extension:
cd apache-jmeter-2.13/bin nano jmeterFind the line like the screenshot below. Set the values of heap size in accordance with the characteristics of the server. The first value HEAP Xms amount of memory allocated to the process when the process start, and the second Xmx — maximum amount of RAM that will be available to process.

If the server without GUI and access it remotely, as in most cases it is better to put JMeter locally to debug and write scripts. Ideally the version should match, but in most cases understands JMeter scripts neighbouring or minor versions. Of course, on the local machine also needs to stand Java himself JMeter.
Proceed to install and configure Yandex.Tank, sufficient should be these steps:
sudo apt-get install python-pip build-essential python-dev libffi-dev gfortran libssl-devsudo -H pip install pip --upgradesudo -H pip install --upgrade setuptoolssudo -H pip install https://api.github.com/repos/yandex/yandex-tank/tarball/masterThen we should tell our gun where to shoot and how. To do this, create a working directory on the machine with the tank configuration file load.ini
mkdir test cd test nano load.ini Contents of the configuration file is a guide to the tank, it should reflect all key points of the test. Here is an example load.ini to test using JMeter:

I think the block [tank] all clear, if you have questions there is a description of each field and a block from the tank. All the fun is in the block [jmeter].
the
Development of the script
It's time to write the first test. To do this, open the client JMeter — most Windows systems need to run as administrator. About how to start to learn JMeter, but at the same time to understand its GUI is well written in this article. We have the same example with a database that is slightly different from normal http requests. The first difference is that PostgreSQL is not supported in JMeter out of the box, so you need download the driver need version. Then you need to put the downloaded .jar in the directory /lib folder of JMeter. This .jar you need to put a similar path on the machine with the tank. Driver figured out, go to the script.
The first thing you need to do is configure the DB connection, to do this, right-click click on Test Plan -> Add -> Config Element -- > JDBC Connection Configuration. The tree will replenish the test configuration element, as in the screenshot:

Clicking on it we will see a lot of required fields. Here it is necessary to pay attention first on the top:
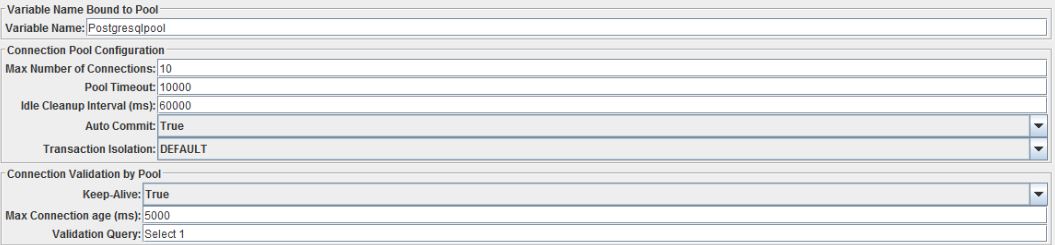
It is important to fill in the Variable Name. This name will be used in JDBC Request (Sampler) for access to the pool sessions. Another is to pay attention to Max Number Of Connections this option limits the number of concurrent connections to the database. The rest of the block, you can leave it as is, if there are no special requirements for timeouts and lifecycle of the connection.

Go to the block in the screenshot above, here we need to enter the data for the database connection. A template like this:
the
-
the
- Database URL: jdbc:postgresql://IPAddress:PortNo/DatabaseName?autoReconnect=true; the
- JDBC Driver class: org.postgresql.Driver; the
- Username: username of database; the
- Password: password of database.
Proceed to further fill tree test. Again, click Test Plan- > Add- > Threads (Users) - > Thread Group.

Before us is a panel of fire control, this is where you enter the number of users, Number of Threads, how much time will be achieved — Ramp-Up Period and with what intensity each new user along with previous will repeat the action. If we need to endlessly query the mark “forever” next to the Loop Count. For the first test, you can set a couple of users with a small number of repetitions. Now go directly to the queries in the database.
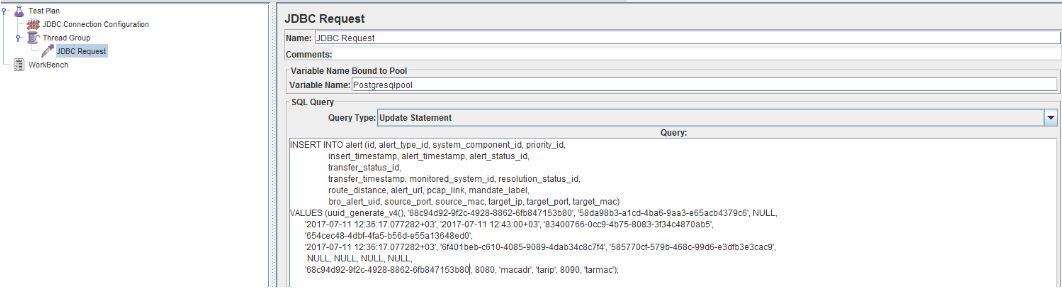
To add to the test plan sampler JDBC request, right click on the right we Thread Group -> Add -> Sampler -- > JDBC Request. We were initially interested in the field Variable Name, it must match the same option from the JBDC Connection Configuration. Then look at the drop down list Query Type, depending on your request there must be an appropriate value, for example, for the SELECT query in the database, you need to select the Select Statement, for INSERT, COPY, and UPDATE — Update Statement, as in our example. In conclusion, sampleroom we need to set the request body, which must correspond to a valid SQL request.
In General, the script is ready, but we need to debug, this is done like this:
the
-
the
- in the right Thread Group the JDBC Request after adding a Debug Sampler. It will display the response received after a request to the database. Added elements similar to the previous Thread Group -> Add -> Sampler - > Debug Sampler; the
- in order to see the results of a sampler, at the end of the test plan we need to monitor the results — you add it like this: Test Plan -> Add — > Listener -> View Results Tree. When you run the script there will be detailing all executed query.
It's time for a test run yet from the JMeter — just click  and click on View Results Tree. After testing the script I got the following results:
and click on View Results Tree. After testing the script I got the following results:

the
Debugging script
See that the first worked successfully and look at the field Response message, it says that the field must be unique. Then turn to the parameterization. There are many ways how to do it, the most unique of them is parameterization using BeanShell PreProcessor. For this we need to insert before our JDBC Request shown above, the preprocessor — Thread Group -> Add -> Pre Processors - > BeanShell PreProcessor. On the preprocessors can be read here or site JMeter. BeanShell PreProcessor is not recommended to use under heavy loads, as a stable and fast option, use a JSR223 PreProcessor + Groovy.

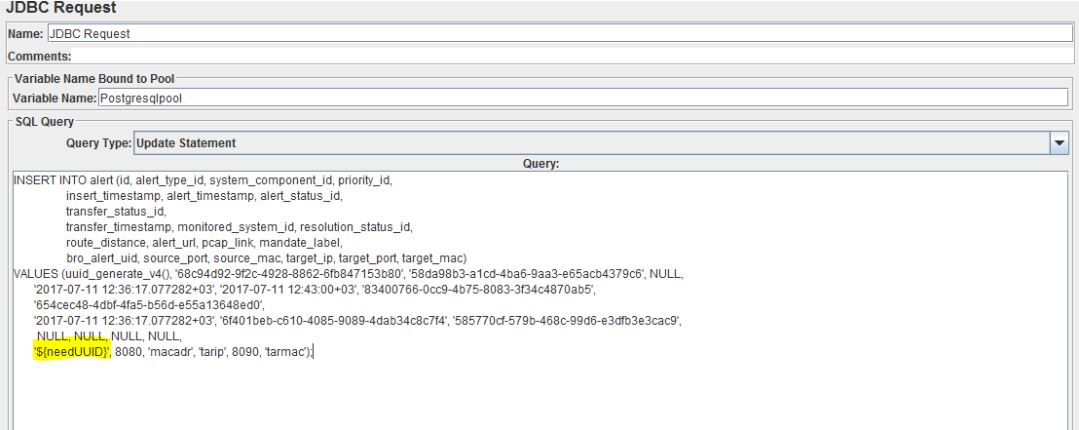
There are no frills — write in java, import the class, declare a variable, assign it to her randomly a variable of the desired format. In order to put the received variable in JMeter variable use vars.put(). Now go to our JDBC Request and add instead of the value in the unique field variable in the format ${needUUID}, the example in the screenshot below:
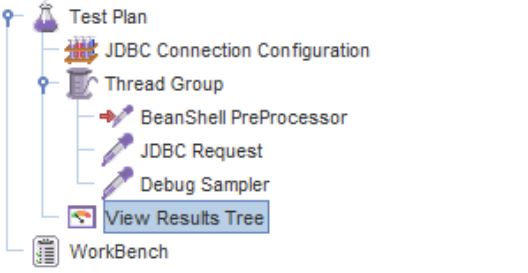
The final structure of our test plan looks like the following:
Do another run of JMeter, look at View Results Tree Debug Sampler and choose up the tab Response Data:
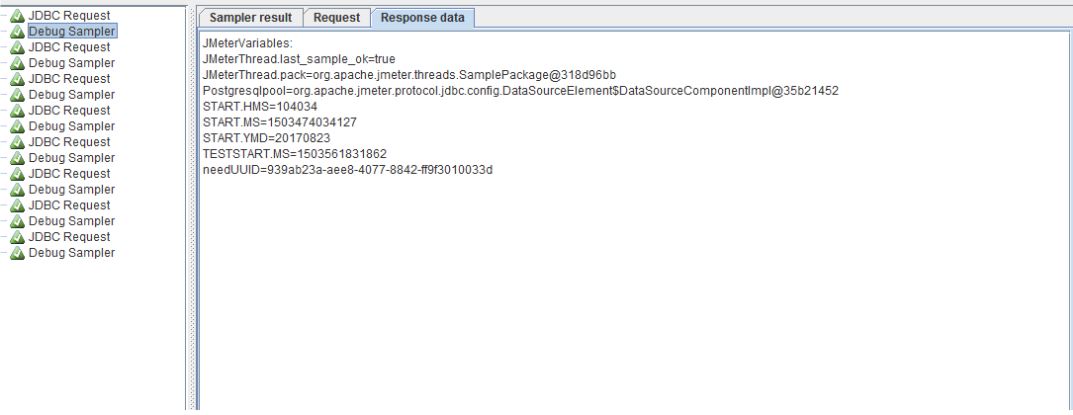
There can be sure that our variable successfully generate and for all requests it is different. When the test is debugged and ready to run we need to remove it from the debug elements, namely, a Debug Sampler and View Results Tree. This is done by simply pressing the right button on the element and select Remove. In any case, make the test after this:
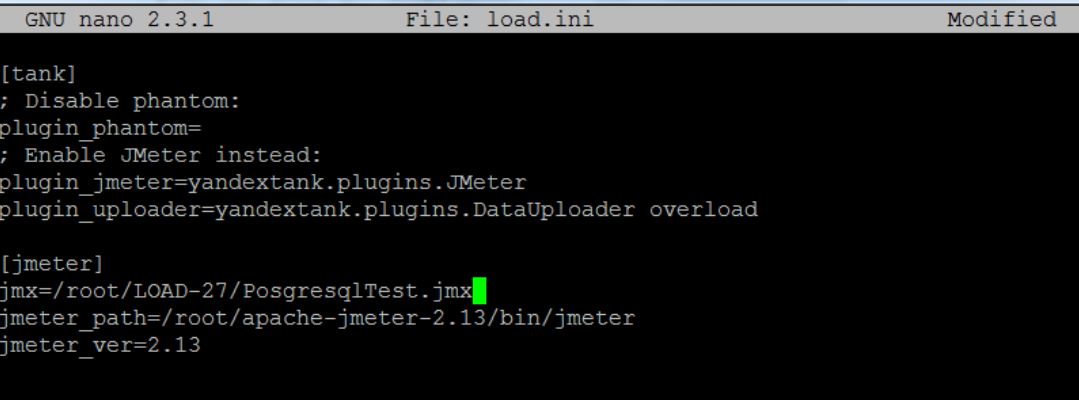
Then save the test and put on the car with the tank. Made it to the parameter “jmx” in the file load.ini and save. Uses absolute addressing. I have looks like this:
It's the first time to understand that at this stage everything works. Before that, we need to control the adding of rows to the database. For this you can use the tool pgAdmin or simply go to the server with the database and do a count of rows before and after execution of the script. Connect to the database runs a similar command:
psql -h IpAddress -d dbName -U UserNameHe count do:
the
select count(*) from alert;Returning to the car with a tank, go to the directory where the load.ini and enter the command to start the tank:
yandex-tankA few seconds after startup a window appears with the current settings of the test. Keep in mind that short tests, the tank may not be able to obtain information about current settings.

the
Monitoring
Checking the performance and testing of the test will move on to setting monitoring. The benefit to configure the monitoring means Overload, it takes minimal effort. Enough the following:
the
-
the
- registration for Overload; the
- get the token by clicking on the profile icon to Overload and select “my api token”; the
- create token.txt in the same folder, and load.ini on the machine with the tank; the
- put the resulting token in token.txt and store; the
- add unit [overload] in the load.ini description from tankers;
Get something like the following contents of the load.ini:
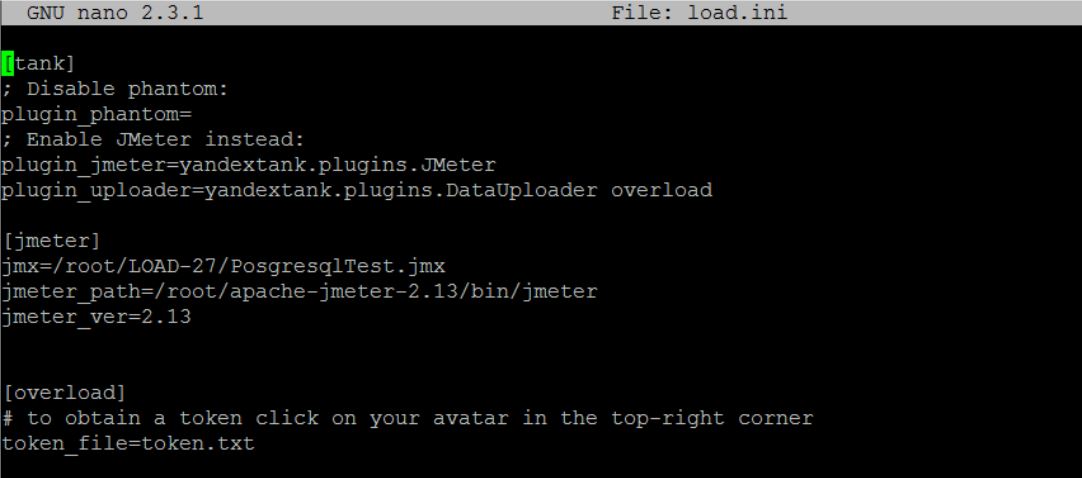
Now after starting the test, we Overload the profile will display the current test and all passed with numerous useful graphs:
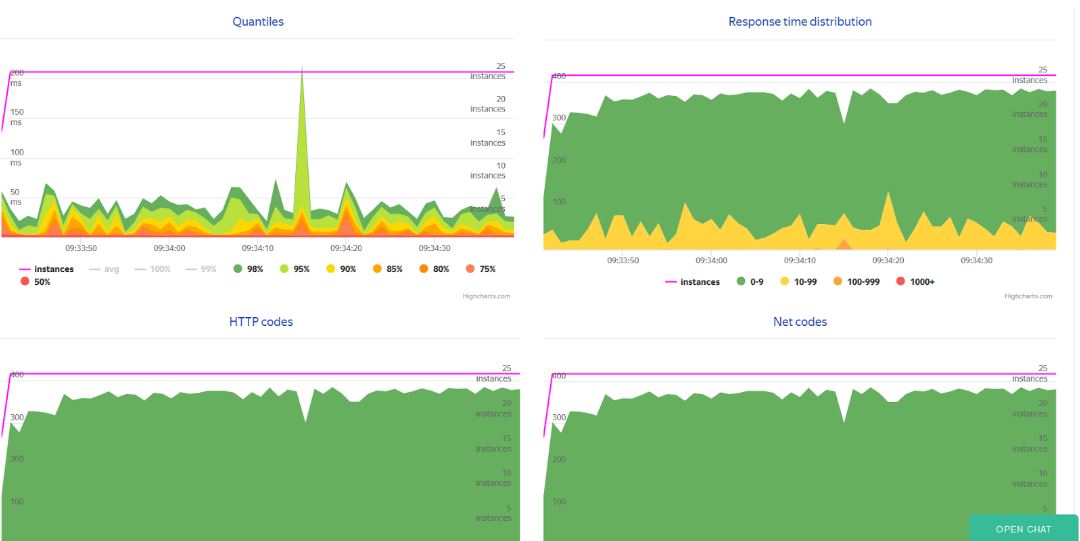
C Overload ended, and now a few words about the other metrics and their monitoring. There are many guides for configuring the monitoring database, and to describe in detail this process, I will not. Suggest to use telegraf for removing metrics server and influxdb for the database. The output of all the metrics can be arranged in Grafana. You can use the installation process in this guide.
Finally, it would be good to say that more recently, namely since version 3.2 JMeter appeared a built-in solution on the basis of influx for monitoring, but there, in contrast to the Overload, you'll have to configure yourself.
That's about it. All good firing!


Комментарии
Отправить комментарий