RandLib. Library of probability distributions on C++17
Library RandLib allows you to work with more than 50 well-known distributions, continuous, discrete, two-dimensional, cyclical and even a singular one. If you need some distribution, enter the name and add a suffix Rand. Interested?
the
Generators random variables
If we want to generate a million random variables from a normal distribution using the standard template library C++, we would write something like
the
std::random_device rd;
std::mt19937 gen(rd());
std::normal_distribution<> X(0, 1);
std::vector<double> data(1e6);
for (double &var : data)
var = X(gen);
Six intuitively not very clear lines. RandLib allows their number to reduce by half.
the
NormalRand X(0, 1);
std::vector<double> data(1e6);
X. Sample(data);
If you need only one random standard normally distributed variable, it can be done in one line
the
double var = NormalRand::StandardVariate();
As you can see, RandLib avoids two things: you can choose the base generator (a function that returns an integer from 0 to RAND_MAX certain) and choose the starting position for a random sequence (the function srand()). This is done in the name of convenience, as many users the choice most likely to anything. In the vast majority of cases the random variables are not generated directly through the underlying generator, using the random variable U, uniformly distributed between 0 and 1, which depends on the base generator. In order to change the generation method U need to use the following guidelines:
the
#define UNIDBLRAND // generator gives a higher resolution due to the combination of two random numbers
#define JLKISS64RAND // generator gives a higher resolution due to generation of 64-bit integers
#define UNICLOSEDRAND // U can return 0 or 1
#define UNIHALFCLOSEDRAND // U can return 0, but never returns 1
By default, U does not return neither 0 nor 1.
the
the generation
In the following table is provided comparing the time to generate one random value in microseconds.
system Features
Ubuntu 16.04 LTS
CPU: Intel Core i7-4710MQ CPU @ 2.50 GHz × 8
OS type: 64-bit
CPU: Intel Core i7-4710MQ CPU @ 2.50 GHz × 8
OS type: 64-bit
| Distribution | STL | RandLib |
|---|---|---|
| 0.017 µs | 0.006 µs | |
| 0.075 µs | 0.018 µs | |
| 0.109 µs | 0.016 µs | |
| 0.122 µs | 0.024 µs | |
| 0.158 µs | 0.101 µs | |
| 0.108 µs | 0.019 µs |
More comparisons
the
| Gamma distribution: | ||
|---|---|---|
| 0.207 µs | 0.09 µs | |
| 0.161 µs | 0.016 µs | |
| 0.159 µs | 0.032 µs | |
| 0.159 µs | 0.03 µs | |
| 0.082 µs | ||
| student Distribution: | ||
| 0.248 µs | 0.107 µs | |
| 0.262 µs | 0.024 µs | |
| 0.33 µs | 0.107 µs | |
| 0.236 µs | 0.039 µs | |
| 0.233 µs | 0.108 µs | |
| Fisher Distribution: | ||
| 0.361 µs | 0.099 µs | |
| 0.319 µs | 0.013 µs | |
| 0.314 µs | 0.027 µs | |
| 0.331 µs | 0.169 µs | |
| 0.333 µs | 0.177 µs | |
| Binomial distribution | ||
| 0.655 µs | 0.033 µs | |
| 0.444 µs | 0.093 µs | |
| 0.873 µs | 0.197 µs | |
| Poisson Distribution: | ||
| 0.048 µs | 0.015 µs | |
| 0.446 µs | 0.105 µs | |
| Negative binomial distribution | ||
| 0.297 µs | 0.019 µs | |
| 0.587 µs | 0.257 µs | |
| 1.017 µs | 0.108 µs |
As you can see, RandLib sometimes 1.5 times faster than STL, sometimes 2, sometimes 10, but never slower.
the
of the distribution Function, the moments and other properties
In addition to generators RandLib provides the ability to calculate probability functions for any of the data distributions. For example, to determine the probability that a random variable with Poisson distribution with parameter a take the value of k you need to call the function P.
the
int a = 5, k = 1;
PoissonRand X(a);
X. P(k); // 0.0336897
It so happened that the capital letter P denotes a function that returns the probability of taking any value for a discrete distribution. Have continuous distributions this probability is equal to zero almost everywhere, so instead, this article considers density, which is denoted by the letter f. In order to calculate the distribution function for both continuous and for discrete distributions we need to call a function F:
the
double x = 0;
NormalRand X(0, 1);
X. f(x); // 0.398942
X. F(x); // 0
Sometimes we need to calculate the function 1-F(x), where F(x) takes very small values. In this case, in order not to lose precision, you should call the function S(x).
If we need to calculate the probability for the whole set of values, then you need to call the function:
the
//x and y are std::vector
X. CumulativeDistributionFunction(x, y); // y = F(x)
X. SurvivalFunction(x, y); // y = S(x)
X. ProbabilityDensityFunction(x, y) // y = f(x) is continuous for
X. ProbabilityMassFunction(x, y) // y = P(x) for discrete
Quantile is a function of p, returns x such that p = F(x). Conforming implementations are also included in each target class RandLib, the corresponding one-dimensional distribution:
the
X. Quantile(p); // returns x = F^(-1)(p)
X. Quantile1m(p); // returns x = S^(-1)(p)
X. QuantileFunction(x, y) // y = F^(-1)(x)
X. QuantileFunction1m(x, y) // y = S^(-1)(x)
Sometimes, instead of functions f(x) or P(k) need to get their corresponding logarithms. In this case, it is best to use the following functions:
the
X. logf(k); // returns x = log(f(k))
X. logP(k); // returns x = log(P(k))
X. LogProbabilityDensityFunction(x, y) // y = logf(x) is continuous for
X. LogProbabilityMassFunction(x, y) // y = logP(x) for discrete
Also RandLib provides the ability to calculate the characteristic function:
the
X. CF(t); // returns a complex value \phi(t)
X. CharacteristicFunction(x, y) // y = \phi(x)
In addition, you can easily get the first four moment, or mathematical expectation, variance, skewness and kurtosis. In addition, the median (F^(-1)(0.5)) and fashion (the point where f or P takes the largest value).
the
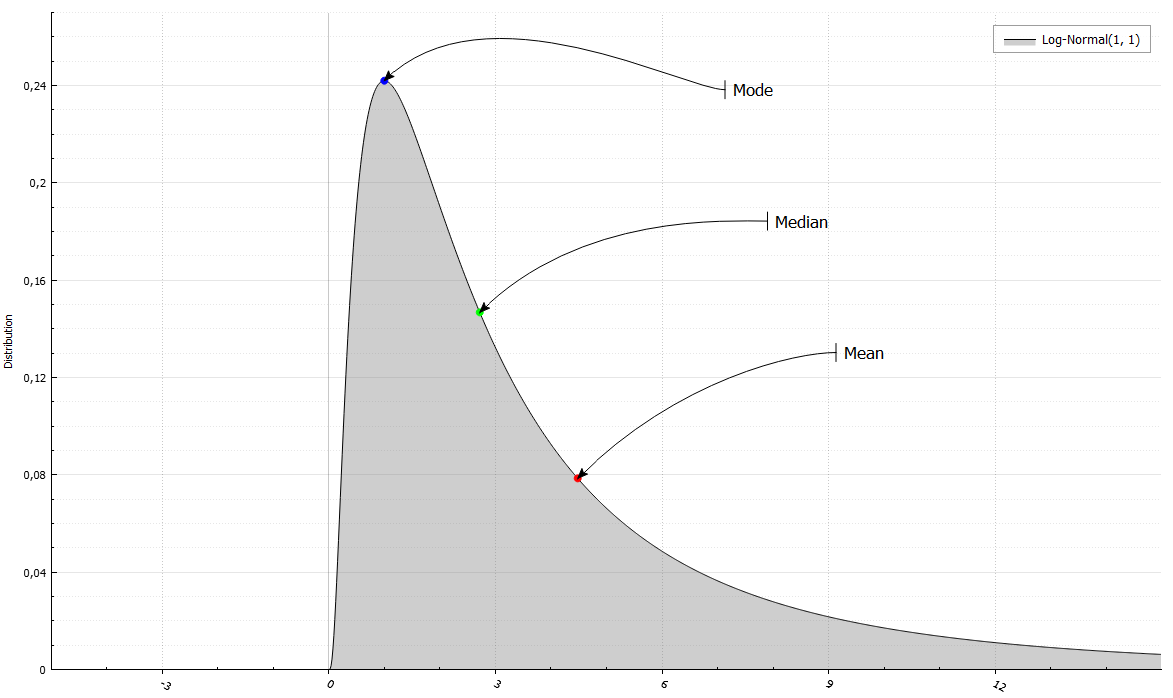
LogNormalRand X(1, 1);
std::cout << "Mean =" << X. Mean()
<< "and Variance =" << X. Variance()
<< "\n Median = " << X. Median()
<< "& Mode = " << X. Mode()
<< "\n Skewness = " << X. Skewness()
<< "and Excess kurtosis =" << X. ExcessKurtosis();
the
Mean = 4.48169 and Variance = 34.5126
Median = 2.71828 and Mode = 1
Skewness = Excess Kurtosis and 6.18488 = 110.936
the
parameter Estimates and statistical tests
From the theory of probability to statistics. For some (not all) classes is a function of the Fit that specifies the parameters that correspond to a certain rating. Consider the example of a normal distribution:
the
using std::cout;
NormalRand X(0, 1);
std::vector<double> data(10);
X. Sample(data);
cout << "True distribution:" << X. Name() << "\n";
cout << "Sample: ";
for (double var : data)
cout << var << " ";
We generated 10 elements from a standard normal distribution. The output needs to something like:
the
True distribution: Normal(0, 1)
Sample: -0.328154 0.709122 -0.607214 1.11472 -1.23726 -0.123584 0.59374 -1.20573 -0.397376 -1.63173
The Fit function in this case will set the parameters corresponding to the estimation of maximum-likelihood:
the
X. Fit(data);
cout << "the Maximum-likelihood estimator:" << X. Name(); // Normal(-0.3113, 0.7425)
As is known, the maximum likelihood for the variance of the normal distribution gives a biased estimate. Therefore, the Fit function has an additional parameter unbiased (default false), which you can configure biasedness / fuzzy data evaluation.
the
X. Fit(data, true);
cout << "UMVU estimator:" << X. Name(); // Normal(-0.3113, 0.825)
For lovers of Bayesian ideology, there are also Bayesian estimation. Structure RandLib makes it very easy to operate a priori and a posteriori distributions:
the
NormalInverseGammaRand prior(0, 1, 1, 1);
NormalInverseGammaRand posterior = X. FitBayes(data, prior);
cout << "Bayesian estimator:" << X. Name(); // Normal(-0.2830, 0.9513)
cout << "(Posterior distribution: "<< posterior.Name() << ")"; // Normal-Inverse-Gamma(-0.2830, 11, 6, 4.756)
the
Tests
How do you know that the generators and distribution functions return the right values? Answer: compare one with the other. For continuous distributions has a function of conducting the Kolmogorov-Smirnov test on the identity of a given sample to the corresponding distribution. The input function takes KolmogorovSmirnovTest order statistics and the level of \alpha, and to output returns true if the sample corresponds to the distribution. Discrete distributions corresponds to the function PearsonChiSquaredTest.
the
Conclusion
This article is written specifically for the part of abrasheva interested in such and is able to assess. Deal, pick, use on health. Main advantages:
the
-
the
- Free of charge the
- Open source the
- Speed the
- Ease of use (my subjective opinion) the
- Lack of dependencies (Yes, nothing)
Link to release.


Комментарии
Отправить комментарий